
A Deep Dive into MongoDB Architecture
Understanding the Document Model, Replica Sets, and the Mechanics of Horizontal Sharding

For decades, the relational database (RDBMS) was the undisputed default for software engineering. If you were building an application, you created tables, defined strict columns, and used SQL to join them together. But as the web evolved, data became messier, more complex, and significantly larger. Constantly running ALTER TABLE to add new columns for rapidly changing applications became a massive bottleneck.

Enter MongoDB.

MongoDB completely abandoned the concept of rows, columns, and rigid schemas. Instead, it embraced the Document Model, becoming the flagship database of the NoSQL movement. Here is a look under the hood at how MongoDB structures data, handles high availability, and scales to petabytes of information.
Note: A petabyte (PB) is a unit of digital information storage equal to 1,000 terabytes (TB) or 1 million gigabytes (GB). It represents one quadrillion bytes and is used to measure massive data sets, such as cloud storage, large-scale data centers, and Big Data analytics.
1. The Core Philosophy: The Document Model
In a relational database like PostgreSQL, if you want to store a user, their blog posts, and their comments, you typically need three separate tables connected by foreign keys. To retrieve the full profile, the database CPU has to perform expensive JOIN operations.
")
MongoDB flips this paradigm. Data that is accessed together should be stored together.

Instead of rows, MongoDB stores data in Documents. These documents are formatted as BSON (Binary JSON).
Note: BSON is a binary-encoded serialization format used primarily by MongoDB for data storage and network transfer. It extends JSON to be lightweight, traversable, and efficient, supporting extra data types like
Date,raw binary data, andObjectId. While MongoDB uses JSON-like queries, it stores documents as BSON for faster parsing and reduced storage overhead.
Collections instead of Tables: A collection groups related documents together.
Dynamic Schemas: Document A in a “Users” collection can have a
twitter_handlefield, while Document B in the exact same collection might not. The database doesn’t force uniformity.Embedded Data: Instead of a separate “Comments” table, a user document can simply contain an array of comment objects embedded directly inside it.
Because you can retrieve a complex, nested data structure with a single query, MongoDB often provides massive performance boosts for read-heavy applications.
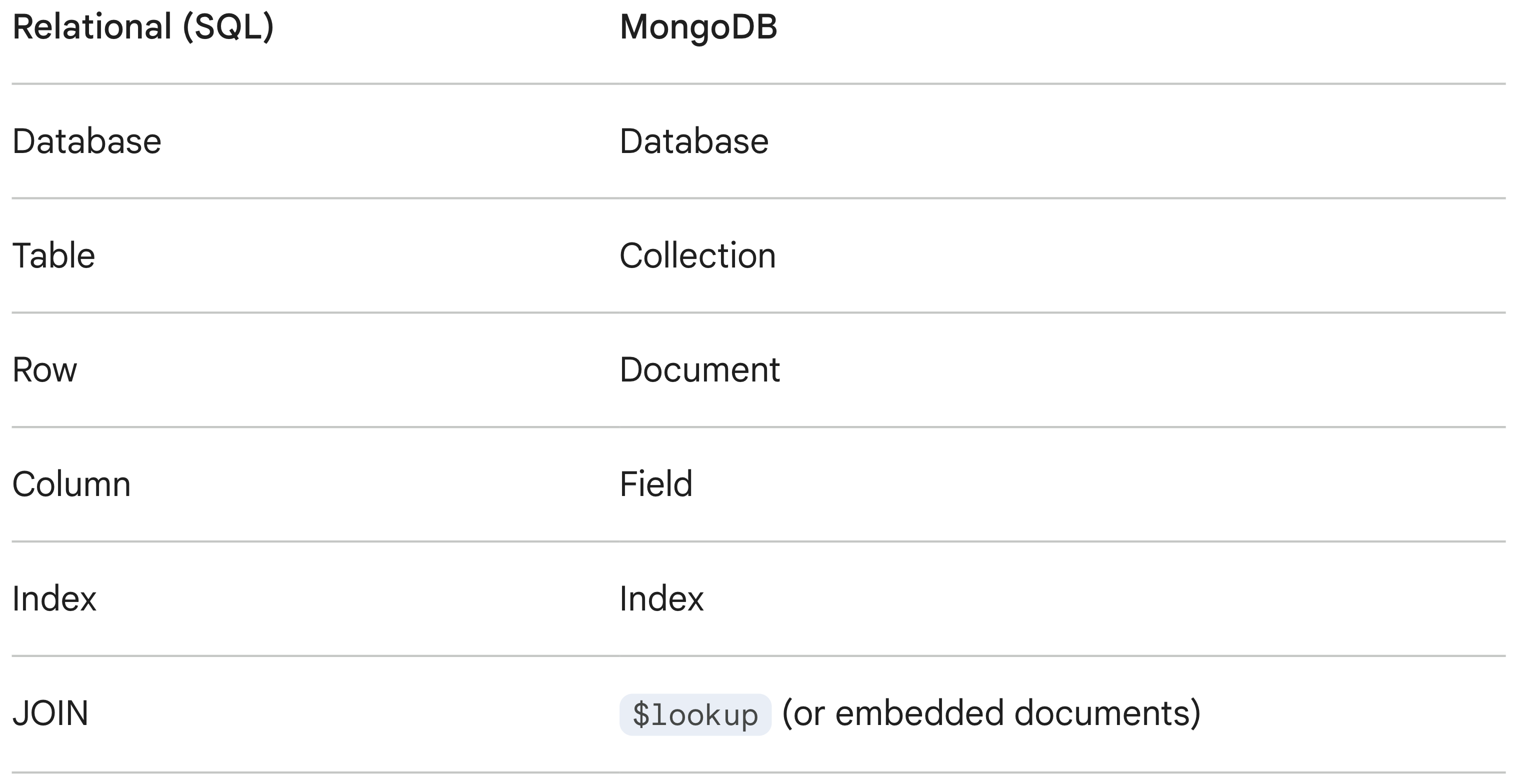
The SQL to MongoDB Translation Guide
𝐋𝐞𝐚𝐫𝐧 𝐭𝐨 𝐛𝐮𝐢𝐥𝐝 𝐆𝐢𝐭, 𝐃𝐨𝐜𝐤𝐞𝐫, 𝐑𝐞𝐝𝐢𝐬, 𝐇𝐓𝐓𝐏 𝐬𝐞𝐫𝐯𝐞𝐫𝐬, 𝐚𝐧𝐝 𝐜𝐨𝐦𝐩𝐢𝐥𝐞𝐫𝐬, 𝐟𝐫𝐨𝐦 𝐬𝐜𝐫𝐚𝐭𝐜𝐡. Get 40% OFF CodeCrafters: https://app.codecrafters.io/join?via=the-coding-gopher
2. High Availability: Replica Sets
If the server running your database catches fire, your application goes down. To prevent this, MongoDB uses a topology called a Replica Set to ensure high availability and data redundancy.

A standard Replica Set consists of a minimum of three nodes:
The Primary Node: This is the only node that accepts write operations from your application. It records every change in a special collection called the
oplog(Operations Log).The Secondary Nodes: These nodes constantly replicate the Primary’s
oplogand apply the changes to their own datasets. They can also be configured to handle read operations to offload traffic from the Primary.
Automatic Failover

If the Primary node crashes or loses network connectivity, the Secondary nodes detect the failure. They immediately hold an “election” using a consensus algorithm. Within seconds, one of the Secondaries is promoted to be the new Primary, and the application continues functioning with virtually zero downtime.
A MongoDB replica set is a group of
mongodinstances that maintain the same dataset, providing high availability, data redundancy, and automatic failover. It consists of one primary node that receives all write operations and multiple secondary nodes that replicate data. A minimum of three nodes is recommended, often arranged in a Primary-Secondary-Secondary (P-S-S) configuration.
3. Horizontal Scaling: Sharding
Replica sets protect you from hardware failure, but what happens when your dataset grows to 10 Terabytes? A single Primary node will eventually run out of RAM, CPU, or disk space.
While traditional SQL databases usually scale vertically (buying a bigger, more expensive server), MongoDB is designed to scale horizontally (adding more cheap servers) using a technique called Sharding.

When you shard a MongoDB database, you slice your massive collection into smaller chunks and distribute them across multiple Replica Sets. The architecture requires three specialized components:
Shards: The actual Replica Sets that store subsets of the data.
Config Servers: A separate Replica Set that stores the metadata. It acts as the map, knowing exactly which chunk of data lives on which Shard.
Query Routers (
mongos): The traffic cops. Your application never connects directly to a Shard. It connects to themongosrouter. If you ask forUser:123, the router checks the Config Servers, finds out that user is on Shard B, forwards the query there, and returns the result to you.

The Shard Key
To divide the data, you must choose a Shard Key (e.g., user_id or zip_code). MongoDB uses this key to algorithmically distribute the documents. Choosing the wrong shard key can lead to “jumbo chunks” or “hot spots” where one server gets 90% of the traffic while the others sit idle, making shard key selection one of the most critical engineering decisions in MongoDB.

The Verdict
MongoDB is an incredibly powerful tool, but it isn’t a silver bullet.
If your application relies on highly structured data with complex, multi-entity transactions (like a double-entry accounting system), a relational database like PostgreSQL is still the superior choice.
However, if you are building an application with rapidly changing data requirements, heavy real-time analytics, mobile app backends, or massive catalogs of unstructured data, MongoDB’s flexible document model and native distributed architecture make it an engineering powerhouse.
this was a great read!