
An Intro to Database Sharding
When a single database server can no longer handle traffic or data size, allowing you to avoid expensive vertical scaling

What is Database Sharding?
When a monolithic database reaches its physical limits, engineers face a hard ceiling. You can only provision so much RAM, CPU, and Disk I/O on a single machine before vertical scaling (scaling up) becomes either technologically impossible or financially prohibitive.

To bypass hardware constraints, distributed systems rely on Database Sharding. Sharding is the architectural process of separating a single, logical dataset and distributing it across multiple, independent physical database nodes.

Here is a technical breakdown of how sharding operates at the infrastructure level, the routing mechanisms required to make it work, and the severe engineering trade-offs it introduces.
1. The Core Architecture: Horizontal Partitioning
In a traditional relational database setup, a table containing one billion rows resides on a single disk volume.

Sharding employs horizontal partitioning. It takes that table and splits it by rows.
Node A stores the first 250 million rows.
Node B stores the next 250 million rows.
Nodes C and D store the rest.
To the application layer, the database still appears as a single logical entity. At the infrastructure layer, it is a cluster of independent database servers operating in parallel. Because the data is distributed, the computational load (reads, writes, and index rebuilds) is fundamentally decentralized, allowing the system to handle significantly higher throughput.
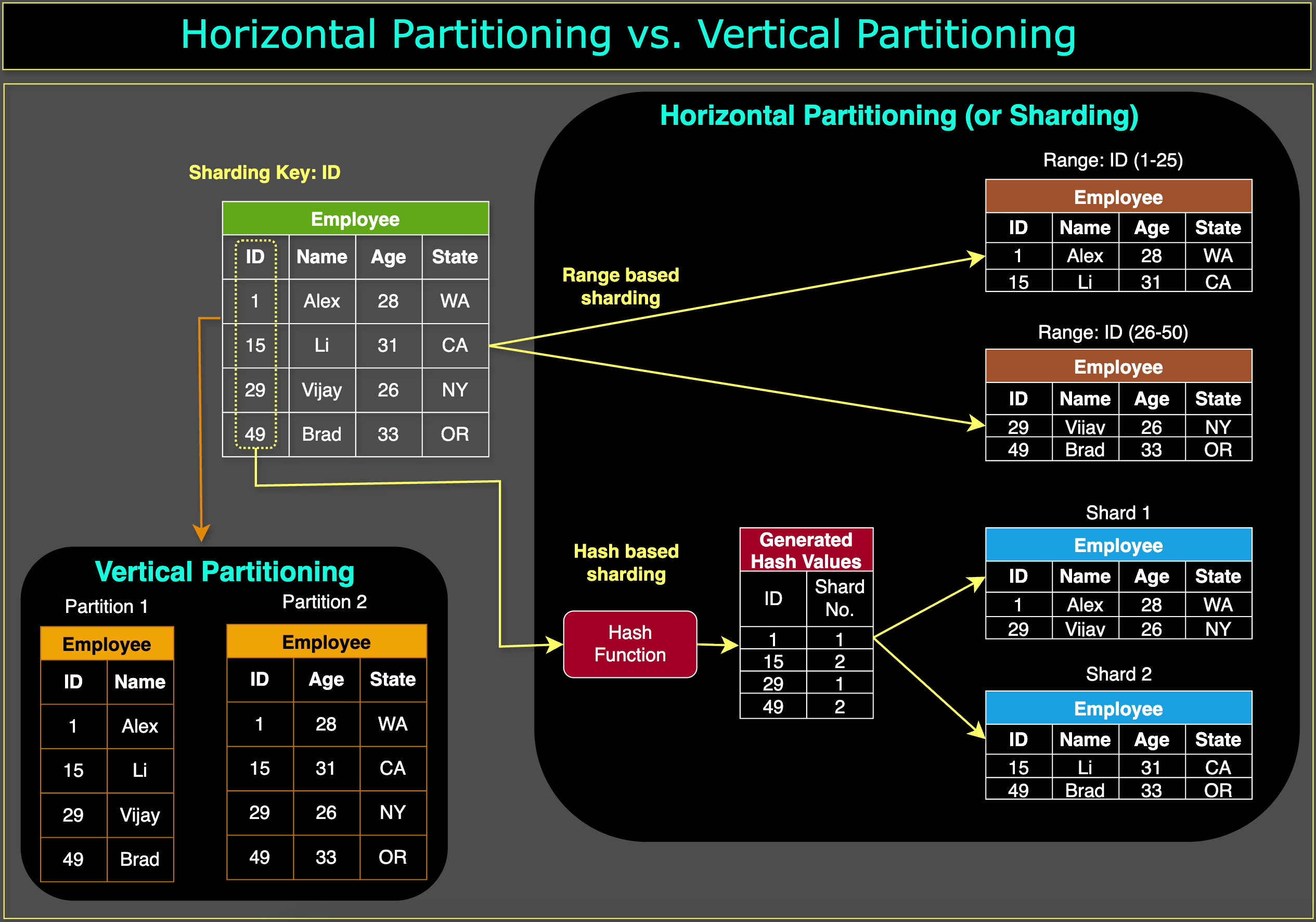
Horizontal partitioning, commonly known as sharding, is a database design technique that splits large tables into smaller, more manageable subsets of rows (partitions). Each partition retains the same schema (columns) but fewer rows, allowing data to be distributed across multiple servers to improve performance, increase storage capacity, and balance load.
2. The Routing Layer
Because data is distributed across multiple instances, the application cannot simply send a SELECT statement to a single IP address. The system requires a mechanism to determine which specific physical node holds the requested data.

This is handled by a Routing Layer, which can be implemented either within the application code itself or as an intermediate proxy service (like Vitess or PgBouncer).
When a query is executed, the routing layer parses it, extracts the determining variable, maps it to the correct physical server, and forwards the query exclusively to that node. The other nodes in the cluster remain unaware of the transaction.

Note: Routing in application code offers high flexibility and domain-aware logic but couples code to infrastructure, requiring redeploys for topology changes. Intermediate proxies (e.g., Nginx, ProxySQL, service meshes) decouple routing from business logic, improving scalability, security, and maintenance by handling load balancing, SSL termination, and path-based routing externally.
𝐋𝐞𝐚𝐫𝐧 𝐭𝐨 𝐛𝐮𝐢𝐥𝐝 𝐆𝐢𝐭, 𝐃𝐨𝐜𝐤𝐞𝐫, 𝐑𝐞𝐝𝐢𝐬, 𝐇𝐓𝐓𝐏 𝐬𝐞𝐫𝐯𝐞𝐫𝐬, 𝐚𝐧𝐝 𝐜𝐨𝐦𝐩𝐢𝐥𝐞𝐫𝐬, 𝐟𝐫𝐨𝐦 𝐬𝐜𝐫𝐚𝐭𝐜𝐡. Get 40% OFF CodeCrafters: https://app.codecrafters.io/join?via=the-coding-gopher
3. Sharding Strategies and the Shard Key
The routing layer relies on a deterministic rule to allocate and retrieve data. This is defined by the Shard Key (or Partition Key). The selection of the shard key dictates the performance and data distribution of the entire cluster. If chosen poorly, it results in unbalanced nodes and system bottlenecks.
There are two primary algorithms for distributing data:
Range-Based Sharding

Data is divided based on continuous, sequential values. For example, routing data based on a created_at timestamp or a sequential customer_id.
Advantage: Highly efficient for range queries (e.g., fetching all records from last week).
Disadvantage: Highly susceptible to Hotspots. If data is sharded by date, the node holding the “current” date will absorb 100% of all incoming write traffic, while historical nodes sit idle.

Hash-Based Sharding

