
Intro to Database Indexing
The only database indexing tutorial you'll ever need

Understanding B-Trees, Hash Tables, and the engineering trade-offs of read optimization.
In relational database systems, querying an unindexed table requires a Full Table Scan. The database engine must sequentially read every row from the physical disk to find matching records, resulting in O(n) time complexity. For tables containing millions of rows, the disk I/O required for these sequential reads becomes a severe performance bottleneck.
To mitigate this, databases utilize Indexes—auxiliary data structures designed to optimize data retrieval speeds. By creating a mapped reference to the underlying table, indexes reduce the amount of data the engine needs to scan.

A database index is a data structure, such as a B-Tree, that improves data retrieval speed on database tables by mapping column values to row locations, acting like a book's index. It enables fast querying (
SELECT,WHERE,ORDER BY) by avoiding full table scans, though it requires extra storage and can slow down write operations (INSERT,UPDATE,DELETE).

Here is a technical breakdown of how primary indexing structures operate at the infrastructure level and the engineering trade-offs they introduce.
1. The B+ Tree Index
When a standard index is created in a relational database like PostgreSQL or MySQL, the engine typically implements a B+ Tree (a variant of the B-Tree).

A B+ Tree is a self-balancing, hierarchical data structure that maintains sorted data and allows for searches, sequential access, insertions, and deletions in logarithmic time.
The architecture of a B+ Tree consists of three node types:
Root Node: The top-level entry point containing search keys and pointers to the next level.
Branch Nodes: Internal nodes that further divide the search space.
Leaf Nodes: The bottom layer of the tree. In a B+ Tree, the actual pointers to the physical rows on the disk (or the row data itself, in clustered indexes) are stored exclusively in the leaf nodes.
Performance and Range Queries
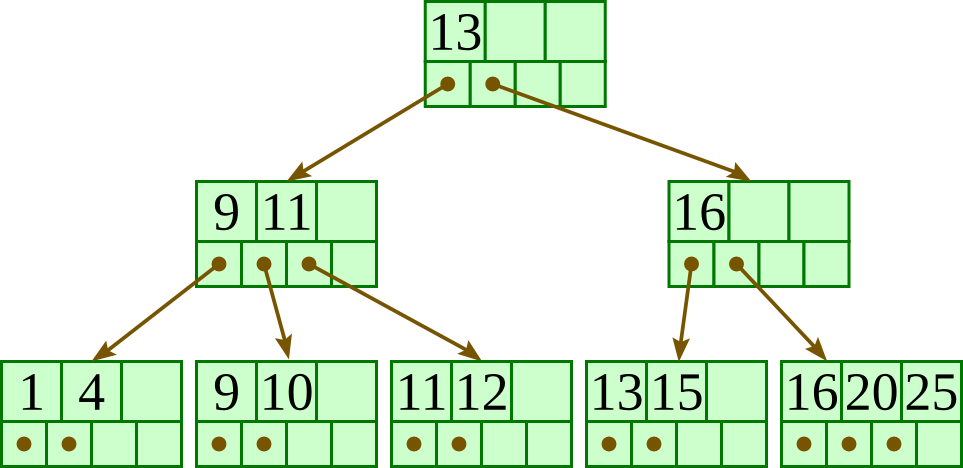
The B+ Tree is strictly balanced, meaning every path from the root to a leaf node has the exact same depth. This guarantees a predictable time complexity of O(log n) for lookups.
Furthermore, the leaf nodes in a B+ Tree are connected via a doubly-linked list. This architecture makes the B+ Tree highly optimized for Range Queries. If an application executes a query like WHERE age BETWEEN 20 AND 30, the database engine traverses the tree to find 20 in O(log n) time, and then sequentially traverses the linked leaf nodes to retrieve the rest of the range.
A B+ tree is a self-balancing, m-ary tree data structure used primarily in databases and file systems to store large amounts of ordered data for fast retrieval. It extends the B-tree by storing all actual data only in leaf nodes—which are linked together for efficient range queries—while internal nodes solely contain keys for navigation.
2. The Hash Index
While B+ Trees are highly versatile, databases also employ Hash Indexes for specific, narrow workloads.

A Hash Index uses a mathematical hashing function to map search keys (e.g., a session token) directly to specific memory buckets where the corresponding row pointers are stored.
The Advantage: Hash indexes provide
O(1)constant-time lookups. The time required to locate a record is mathematically independent of the table’s total size, making them highly efficient for exact equality matches (WHERE token = 'abc').The Limitation: Hash functions obfuscate the natural order of the data. Consequently, hash indexes cannot evaluate ranges (
>,<), perform partial/prefix matches, or assist with sorting operations (ORDER BY). If an application attempts a range query on a hash-indexed column, the database must revert to a full table scan.
𝐋𝐞𝐚𝐫𝐧 𝐭𝐨 𝐛𝐮𝐢𝐥𝐝 𝐆𝐢𝐭, 𝐃𝐨𝐜𝐤𝐞𝐫, 𝐑𝐞𝐝𝐢𝐬, 𝐇𝐓𝐓𝐏 𝐬𝐞𝐫𝐯𝐞𝐫𝐬, 𝐚𝐧𝐝 𝐜𝐨𝐦𝐩𝐢𝐥𝐞𝐫𝐬, 𝐟𝐫𝐨𝐦 𝐬𝐜𝐫𝐚𝐭𝐜𝐡. Get 40% OFF CodeCrafters: https://app.codecrafters.io/join?via=the-coding-gopher
3. The Engineering Trade-offs: The Write Penalty

A common anti-pattern in database design is over-indexing. Indexes are independent data structures that require physical compute and storage resources to maintain. Every index added to a schema introduces significant architectural trade-offs:
Storage Overhead: Indexes consume disk space. Indexing multiple columns on a massive table can easily double or triple the total storage footprint of the database.
The Write Penalty: Indexes degrade write performance. Whenever an
INSERT,UPDATE, orDELETEoperation is executed against the base table, the database engine must synchronously update the base data and every single index associated with that table. For B+ Trees, this includes the computational overhead of mathematically rebalancing the tree structure.
In a high-throughput transactional database, applying too many indexes will severely bottleneck write operations.
Strategy Summary

Optimizing a database schema requires selecting the appropriate index type based on query patterns while strictly limiting the total number of indexes to preserve write latency.
B+ Tree: Delivers
O(log n)time complexity. It is optimal for general purpose queries, sorting (ORDER BY), and range queries (>,<,BETWEEN), but is inefficient for full-text search across large text blobs.Hash: Delivers
O(1)time complexity. It is optimal for high-frequency exact equality matches (=), but cannot process sorting, ranges, or prefix matching.Bitmap: Utilizes fast bitwise operations. It is optimal for low-cardinality data (e.g., boolean flags, fixed categories) in analytical workloads, but causes severe performance degradation on tables with high-frequency writes.