
Precision vs. Recall vs. F1 Score vs. ROC-AUC
A Guide for Data Scientists Who Think from First Principles

A definitive guide to the confusion matrix and the math behind evaluating real-world machine learning models.
Imagine you are building a machine learning model to detect credit card fraud. Out of 10,000 transactions, exactly 100 are fraudulent.
You train your model, test it, and the dashboard proudly displays: 99% Accuracy. You deploy it to production, expecting a promotion. But the next day, your company loses millions of dollars to fraudsters.
What went wrong? You open the logs and realize your model simply predicted “Not Fraud” for every single transaction. Because 9,900 out of 10,000 transactions were legitimate, the model was technically 99% accurate. It was also completely, undeniably useless.
This is the Accuracy Paradox. In the real world, datasets are rarely balanced. To understand how good a classification model actually is, we have to throw “accuracy” in the trash and look at the underlying math of how it makes mistakes.
The Accuracy Paradox occurs when a predictive model achieves high accuracy by simply predicting the majority class in highly imbalanced datasets, offering little real predictive power. A model can appear 95% accurate while failing completely to identify the minority class of interest, such as fraud detection or disease diagnosis.
1. The Foundation: The Confusion Matrix
Before we can calculate any advanced metrics, we have to map out exactly how our model is succeeding and failing. We do this by dropping every prediction into one of four buckets in a Confusion Matrix.
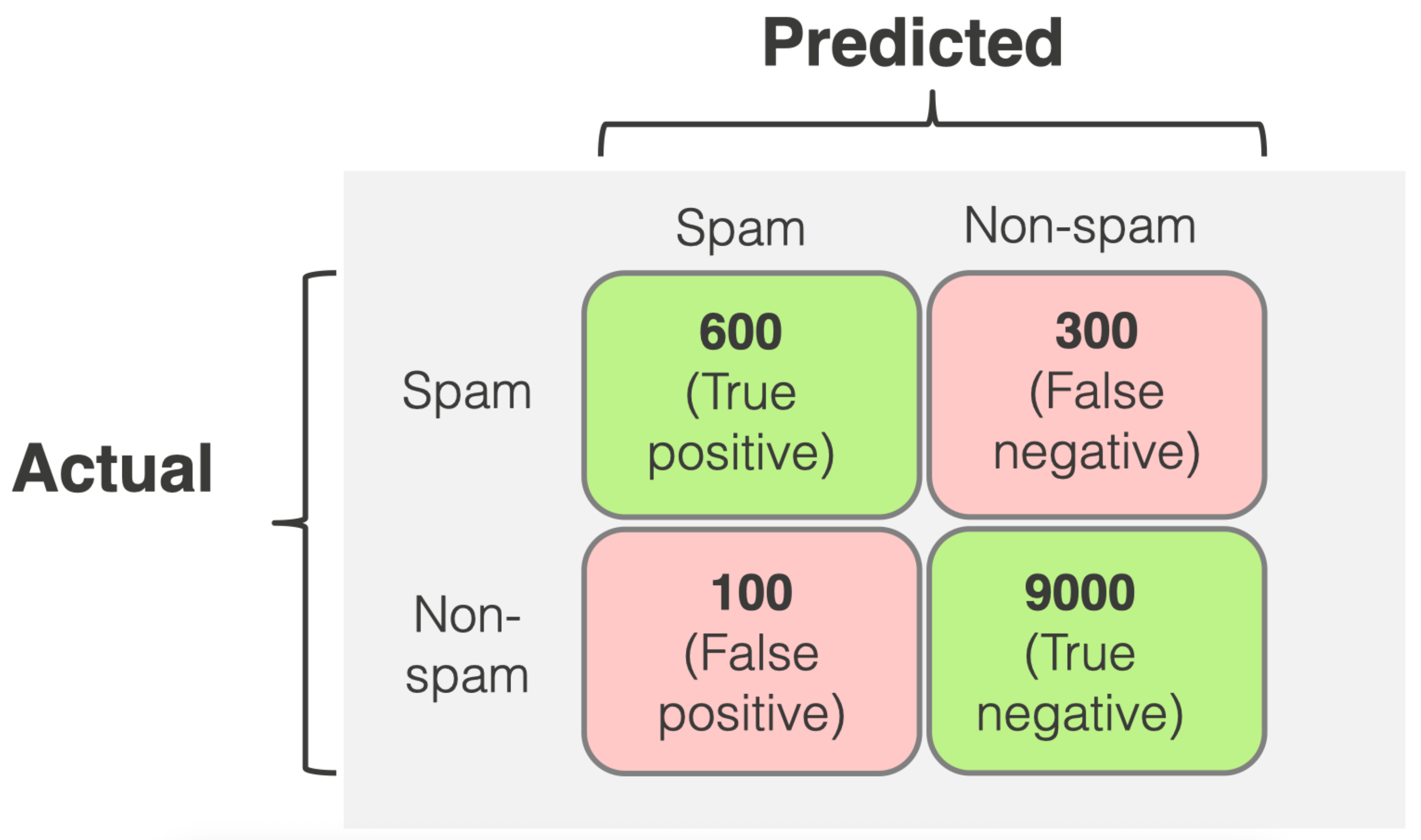
Let’s stick to the fraud detection example, where a “Positive” prediction means the model flagged a transaction as fraud.

With these four buckets, we can calculate the metrics that actually matter.
2. The Tug-of-War: Precision vs. Recall
Precision and Recall are the two most critical metrics in classification, and they are locked in a perpetual tug-of-war. You usually have to sacrifice one to improve the other.
Precision: “Quality over Quantity”
Precision asks: Out of all the transactions my model flagged as fraud, how many were actually fraud?
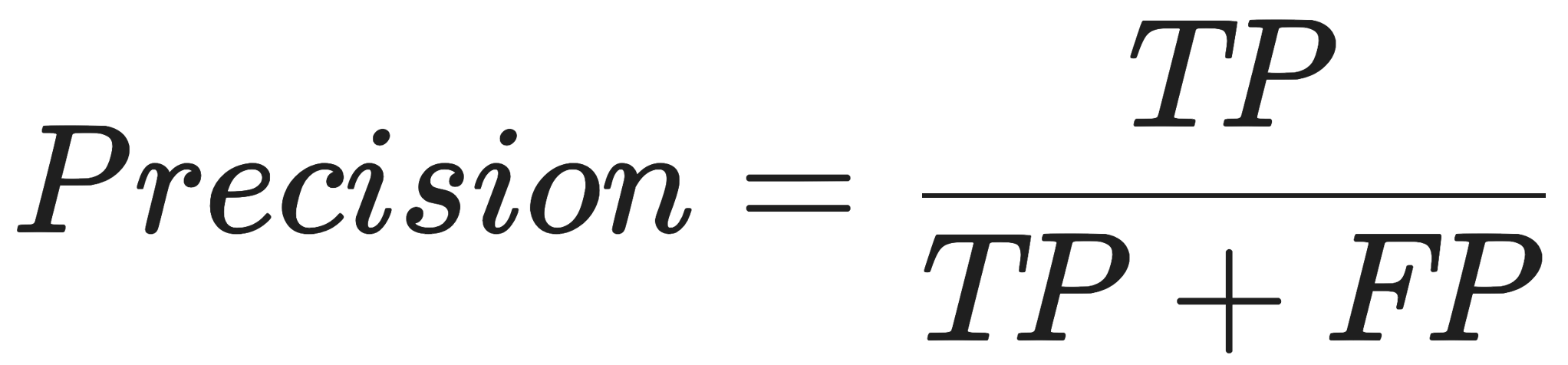
If your model has high precision, it is incredibly trustworthy. When it cries wolf, there is almost certainly a wolf. However, a highly precise model is often overly cautious, meaning it might let a lot of sneaky fraudsters slip through just to avoid annoying innocent customers with false alarms.
Recall (Sensitivity): “Leave No Stone Unturned”
Recall asks: Out of all the actual fraud happening in the real world, how much of it did my model catch?
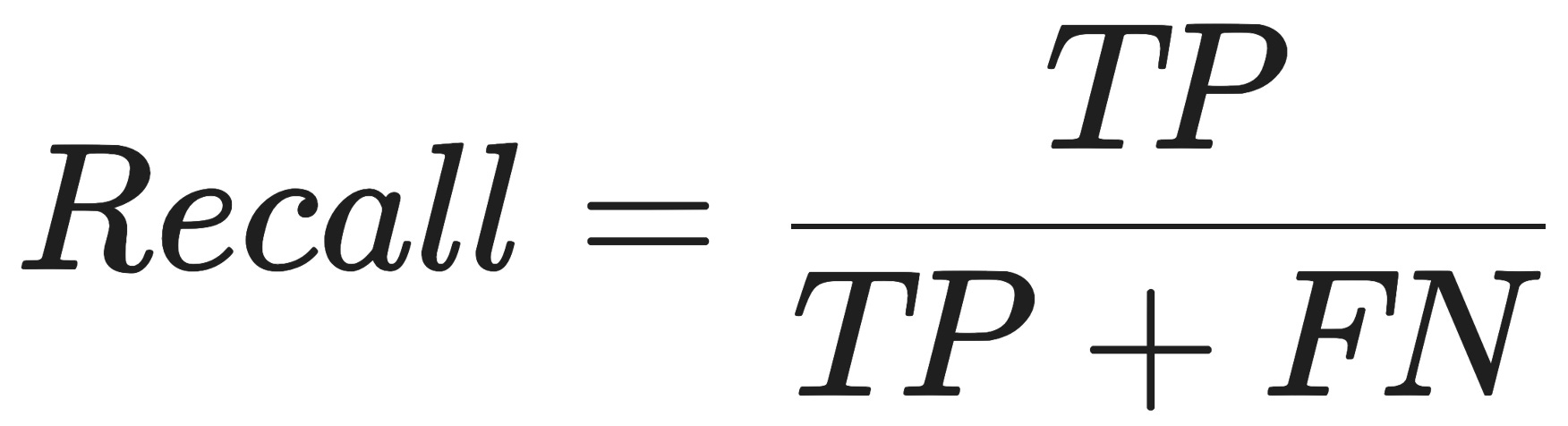
If your model has high recall, it is casting a massive net. It is designed to catch absolutely everything suspicious. The downside? It will generate a ton of false positives, blocking legitimate customers left and right.
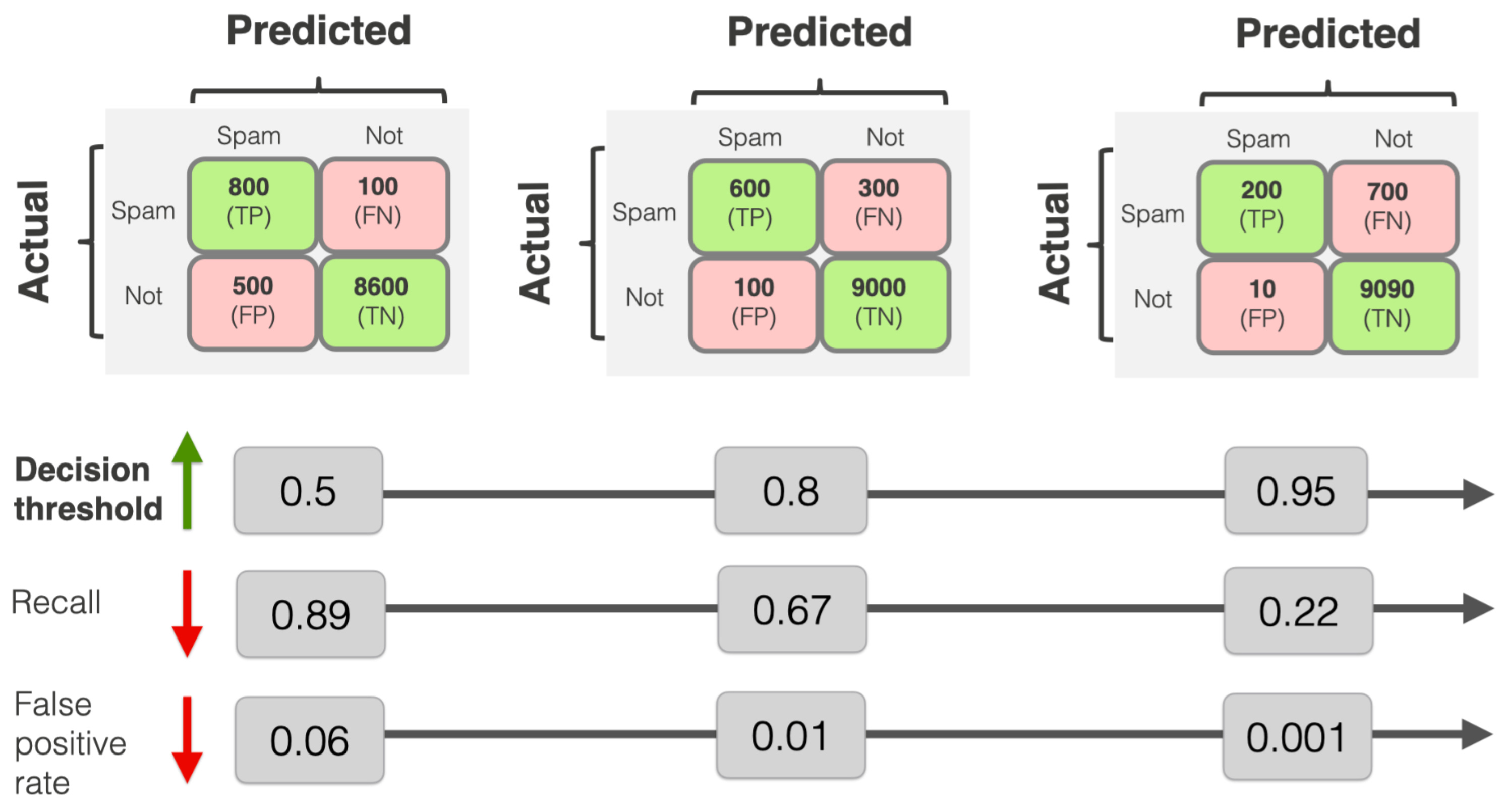
The Trade-off: Do you want to block a few innocent customers to ensure no money is stolen (Optimize for Recall)? Or do you want to ensure no customer is ever inconvenienced, even if a few fraudsters get away (Optimize for Precision)?
Precision measures the accuracy of positive predictions (how many selected items are relevant), while recall measures the ability to find all relevant instances (how many actual positives were found). High precision minimizes false positives, whereas high recall minimizes false negatives. They are often balanced using the F1 score.
𝐋𝐞𝐚𝐫𝐧 𝐭𝐨 𝐛𝐮𝐢𝐥𝐝 𝐆𝐢𝐭, 𝐃𝐨𝐜𝐤𝐞𝐫, 𝐑𝐞𝐝𝐢𝐬, 𝐇𝐓𝐓𝐏 𝐬𝐞𝐫𝐯𝐞𝐫𝐬, 𝐚𝐧𝐝 𝐜𝐨𝐦𝐩𝐢𝐥𝐞𝐫𝐬, 𝐟𝐫𝐨𝐦 𝐬𝐜𝐫𝐚𝐭𝐜𝐡. Get 40% OFF CodeCrafters: https://app.codecrafters.io/join?via=the-coding-gopher
3. The F1 Score: The Peacemaker
Often, you don’t want to choose sides. You want a model that is reasonably precise and has decent recall.
You might think you can just take the standard average of Precision and Recall. You can’t. If a model has a Recall of 100% (it flags literally everything as fraud) and a Precision of 2% (it’s mostly wrong), a simple average would give it a respectable 51%. That’s misleading.
Instead, we use the F1 Score, which is the harmonic mean of Precision and Recall.
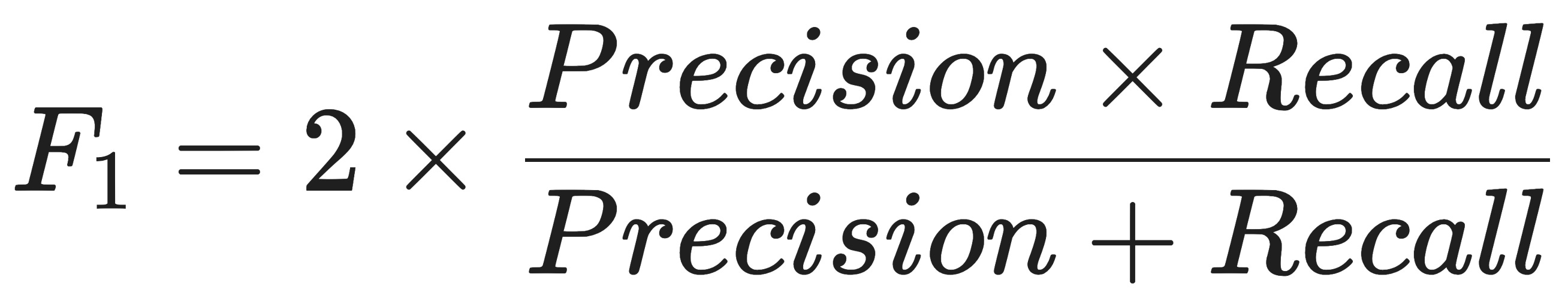

n) by the sum of the reciprocals of each value. It is defined as the reciprocal of the arithmetic mean of the reciprocals.Because it uses multiplication in the numerator, the F1 Score heavily punishes extreme disparities. If either Precision or Recall drops to near zero, the entire F1 Score collapses. An F1 Score is only high if both Precision and Recall are high and balanced.
4. ROC-AUC: The Big Picture
Precision, Recall, and F1 are great, but they evaluate your model at a single, specific threshold.
When a model predicts fraud, it doesn’t just output “Yes” or “No”. It outputs a probability (e.g., “I am 82% sure this is fraud”). As the engineer, you have to decide where to draw the line. Do you flag everything above 50%? 80%? 99%?
Changing that threshold changes your Precision and Recall entirely. How do you evaluate the model’s overall intelligence, regardless of where you draw the line?
You use the ROC-AUC (Receiver Operating Characteristic - Area Under the Curve).
The ROC Curve
Imagine testing your model at every single possible threshold (from 0% to 100%). At each threshold, you plot a point on a graph:
Y-Axis: True Positive Rate (Recall)
X-Axis: False Positive Rate (How many innocents you falsely flagged).
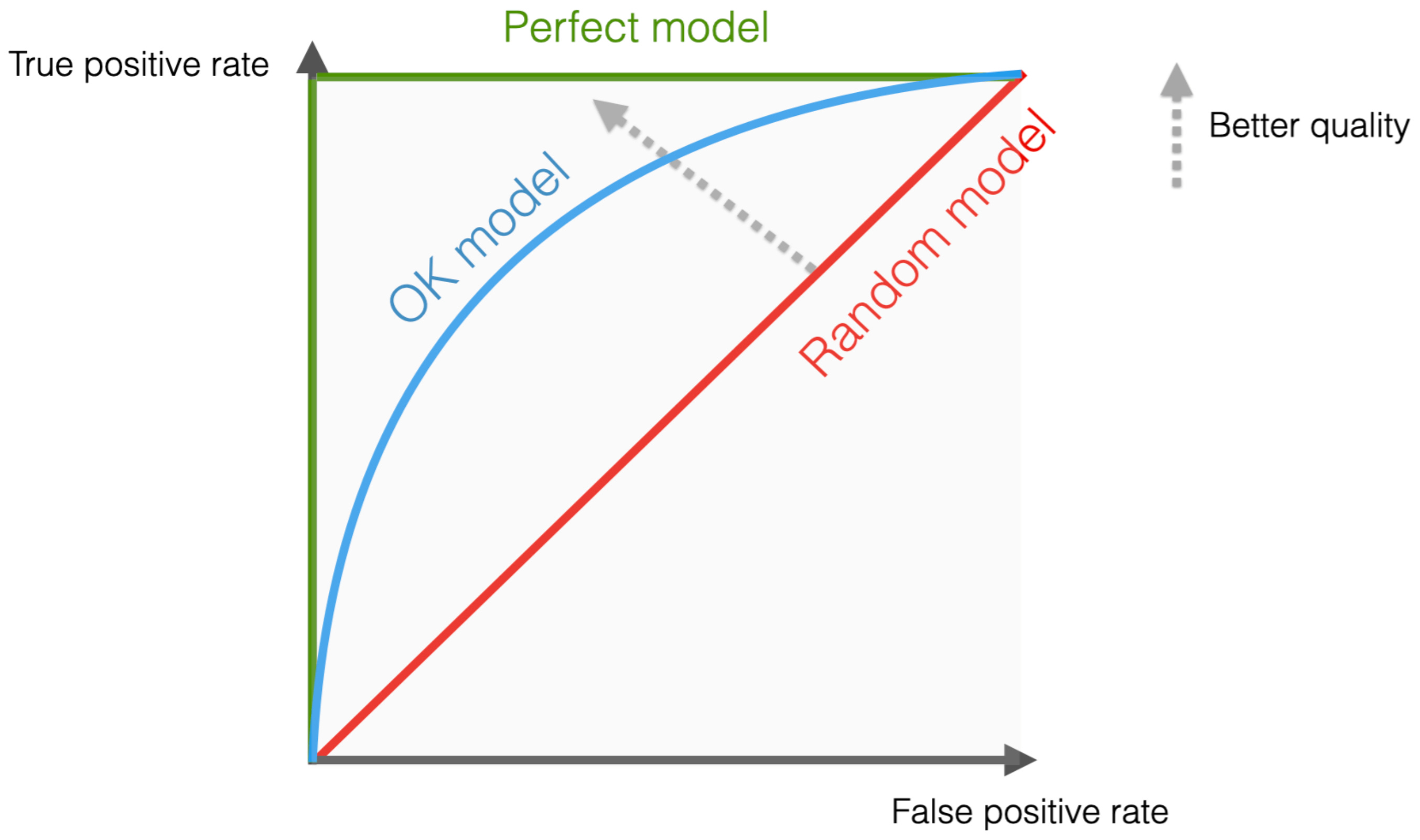
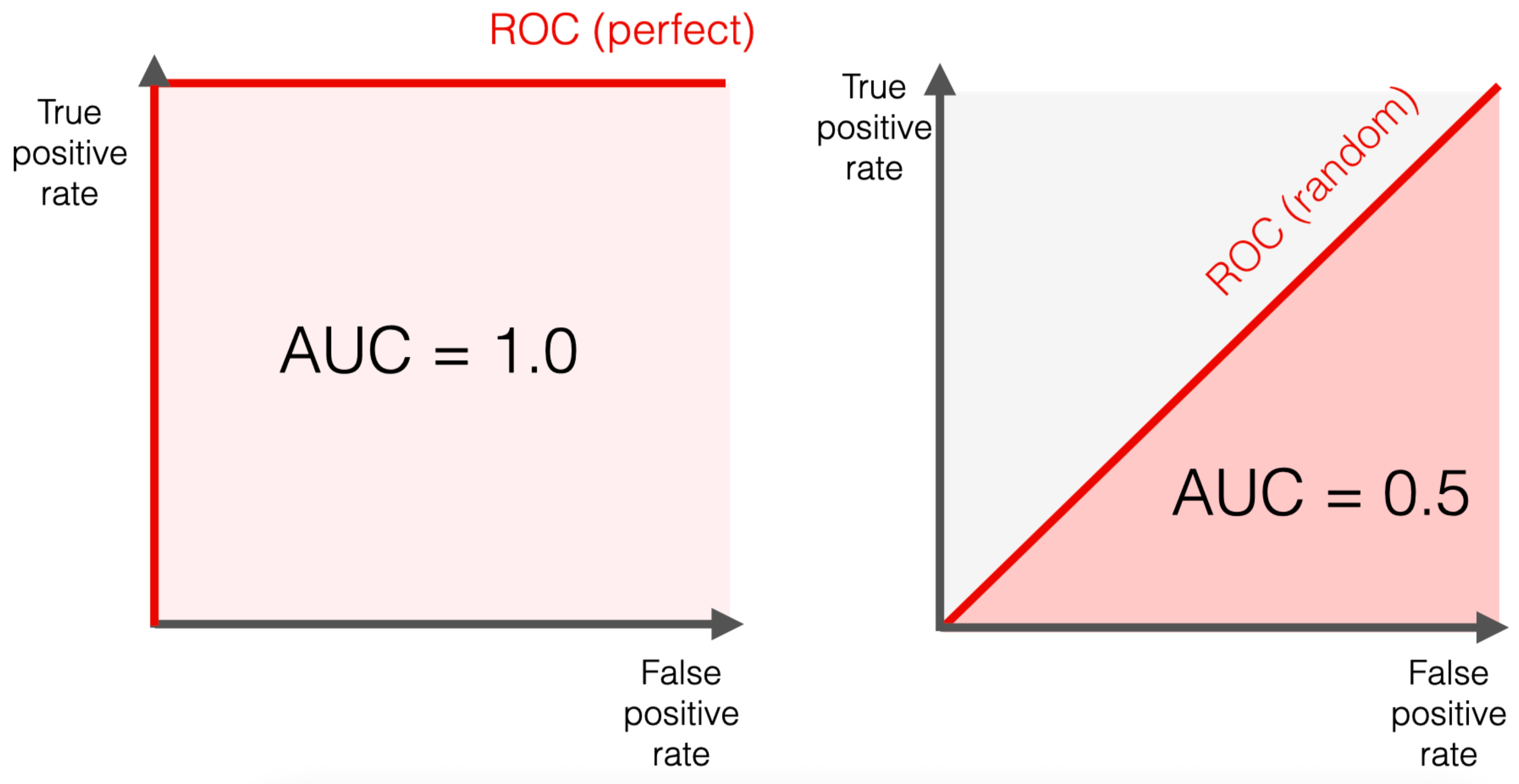
A terrible model (essentially just guessing randomly) will draw a straight diagonal line across the graph. A perfect model will shoot straight up the Y-axis and horizontally across the top.
The AUC (Area Under the Curve)
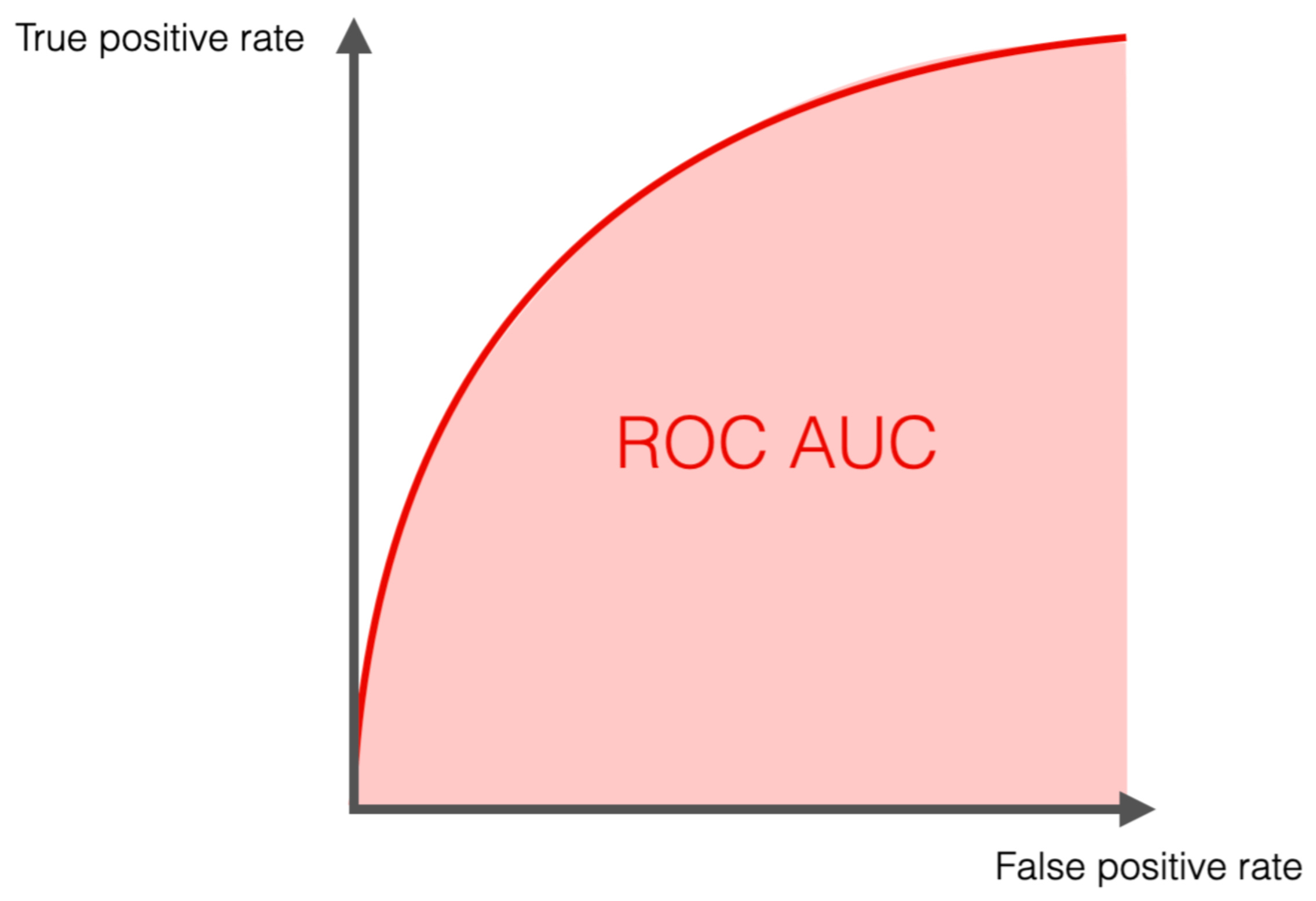
The AUC is simply the total area underneath that ROC curve, represented as a number between 0 and 1.
AUC = 0.5: The model is flipping a coin. It has no idea what it’s doing.
AUC = 1.0: The model is omniscient. It perfectly separates the fraud from the normal transactions.
AUC = 0.85: The model is quite good. Specifically, it means there is an 85% chance that the model will rank a randomly chosen fraudulent transaction higher than a randomly chosen normal transaction.
The Verdict
Evaluating machine learning models isn’t about finding a single magic number; it’s about aligning mathematical metrics with business reality.
If you are building a spam filter, a false positive is annoying (an important email goes to junk), so you optimize for Precision. If you are building an AI to detect cancer on X-rays, a false negative is deadly, so you optimize for Recall. And if you need to compare two different algorithms to see which is fundamentally better at separating classes, you look at the ROC-AUC.
Accuracy is for textbooks. Precision, Recall, F1, and AUC are for production!
soooo good!