
SQL vs. NoSQL Databases Explained
ACID Compliance, Schema Flexibility, and Distributed Data

The end of the “one size fits all” database: How to navigate schemas, horizontal scaling, and the CAP Theorem.
For the first forty years of commercial software engineering, the database world was a monolith. If you had data, you put it in a Relational Database Management System (RDBMS) like Oracle, MySQL, or PostgreSQL. You defined strict columns, normalized your data into dozens of tables, and used SQL to glue it all back together.

Then came the modern web. Social media, IoT devices, and global streaming services began generating data at a velocity and variety that traditional relational databases simply weren’t physically designed to handle. The industry needed a rebellion, and it got one: NoSQL (Not Only SQL).

Today, the most critical architectural decision you will make isn’t what language you write your backend in—it’s how you store your data. Here is a technical breakdown of the fundamental engineering trade-offs between Relational and NoSQL databases.
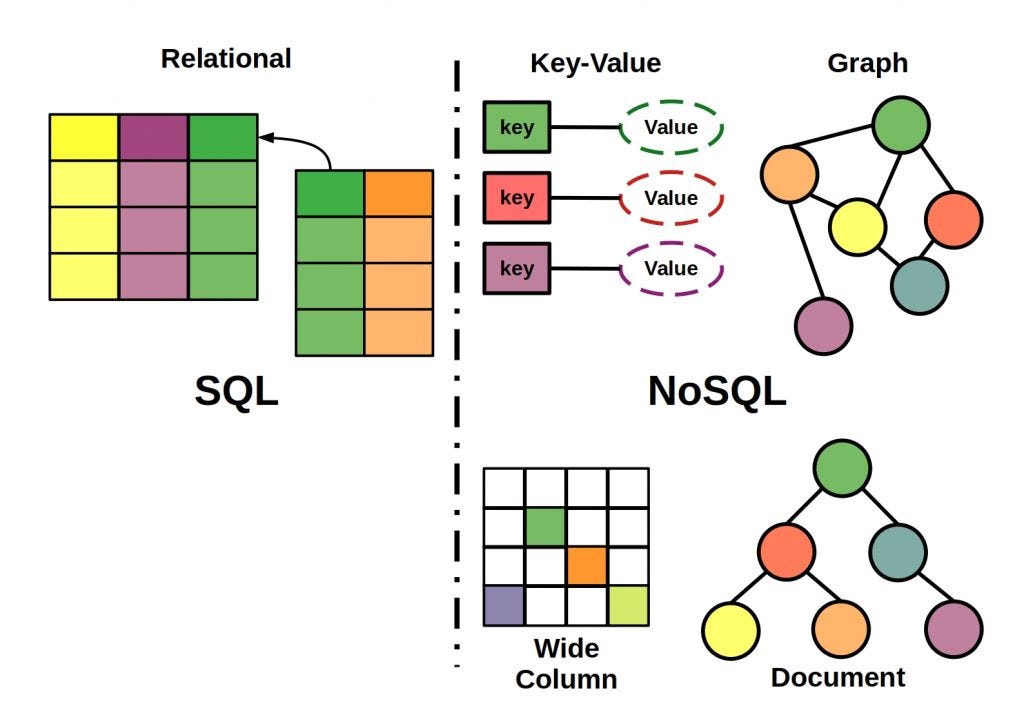
1. The Relational Paradigm: Strict Rules and ACID Guarantees
Relational databases are built on a mathematical concept called relational algebra. They organize data into highly structured tables consisting of rows and columns.
The Power of Normalization
In the SQL world, duplication is a sin. If a user writes a comment on a blog post, you don’t store the user’s name in the comment record. You store a user_id (a Foreign Key) that points to the Users table. This is called Normalization. It ensures that if a user changes their name, you only have to update it in exactly one place. When you need the full picture, the database CPU performs a JOIN operation to stitch the tables together on the fly.

ACID Compliance
The crown jewel of the relational database is ACID (Atomicity, Consistency, Isolation, Durability). If you are building a banking application and transferring $100 from Account A to Account B, the database guarantees that both operations succeed, or neither succeed. There is no scenario where a server crashes midway through and the money vanishes into thin air. The system is mathematically rigorous.

The Trade-off: The rigidity of schemas means that if you have 100 million rows and need to add a new column, the ALTER TABLE operation can lock the database and cause massive downtime. Furthermore, performing complex JOIN operations across massive datasets consumes heavy CPU power.
2. The NoSQL Rebellion: Flexibility and Eventual Consistency
NoSQL is not a single technology; it is an umbrella term for databases that reject the rigid table model. The most popular paradigm is the Document Store (like MongoDB or Couchbase), but NoSQL also includes Key-Value stores (Redis), Column-Family stores (Cassandra), and Graph databases (Neo4j).

Denormalization and Flexibility
In a NoSQL Document database, data that is accessed together is stored together. Instead of foreign keys and JOINs, you store data as a self-contained JSON/BSON object. A blog post document might contain an array of all its comments embedded directly inside it.
There is no strict schema. Document A can have a twitter_handle field, and Document B can omit it entirely. You never have to run an ALTER TABLE migration again.
BASE Semantics
To achieve massive scale, NoSQL databases often trade the strictness of ACID for BASE (Basically Available, Soft state, Eventual consistency). If you update a user’s profile picture, it might take a few milliseconds (or even seconds in a massive cluster) for that change to replicate to every server around the world. For a brief moment, two users might see two different profile pictures. For a social network, this is perfectly fine; for a stock trading platform, it’s catastrophic.

ACID (Atomicity, Consistency, Isolation, Durability) and BASE (Basically Available, Soft State, Eventual Consistency) are database transaction models that dictate how a system prioritizes data integrity versus availability and scalability. SQL (relational) databases typically follow ACID principles, while NoSQL (non-relational) databases generally use the BASE model.
𝐋𝐞𝐚𝐫𝐧 𝐭𝐨 𝐛𝐮𝐢𝐥𝐝 𝐆𝐢𝐭, 𝐃𝐨𝐜𝐤𝐞𝐫, 𝐑𝐞𝐝𝐢𝐬, 𝐇𝐓𝐓𝐏 𝐬𝐞𝐫𝐯𝐞𝐫𝐬, 𝐚𝐧𝐝 𝐜𝐨𝐦𝐩𝐢𝐥𝐞𝐫𝐬, 𝐟𝐫𝐨𝐦 𝐬𝐜𝐫𝐚𝐭𝐜𝐡. Get 40% OFF CodeCrafters: https://app.codecrafters.io/join?via=the-coding-gopher
3. The Scaling Dilemma: Vertical vs. Horizontal
The single biggest architectural difference between the two paradigms comes down to how they handle massive growth.

SQL: Scaling Vertically (Scaling Up)
Because relational databases rely heavily on JOINs, all the data needs to live on the same physical machine. Performing a JOIN between a table on Server A and a table on Server B across a network introduces unacceptable latency. Therefore, to scale a SQL database, you must scale vertically. You buy a bigger server with more RAM, more CPU cores, and faster SSDs. Eventually, you hit a physical and financial ceiling.
NoSQL: Scaling Horizontally (Scaling Out)
Because NoSQL databases encourage denormalized, self-contained documents, they are beautifully designed for distributed systems. If your database grows to 50 Terabytes, you don’t buy a $100,000 supercomputer. You buy fifty cheap commodity servers and use Sharding to split the data across them algorithmically. You scale infinitely by simply racking more servers.
4. The Law of the Land: The CAP Theorem
You cannot discuss databases without discussing the CAP Theorem. This computer science principle states that in any distributed data store, you can only guarantee two of the following three traits:
Consistency (C): Every read receives the most recent write or an error.
Availability (A): Every request receives a non-error response, without the guarantee that it contains the most recent write.
Partition Tolerance (P): The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.

Because networks will eventually fail, Partition Tolerance (P) is a non-negotiable requirement for distributed systems. That means engineers must choose between Consistency and Availability.
Relational Databases generally lean toward CP (Consistency and Partition Tolerance). If the network fragments, a SQL database will often lock down and refuse reads/writes to guarantee data isn’t corrupted.
NoSQL Databases like Cassandra or DynamoDB lean toward AP (Availability and Partition Tolerance). If the network fragments, they will keep serving traffic, accepting that the data might be temporarily stale (Eventual Consistency).
The Verdict

Choosing the right database is about understanding the shape of your data and the requirements of your business.
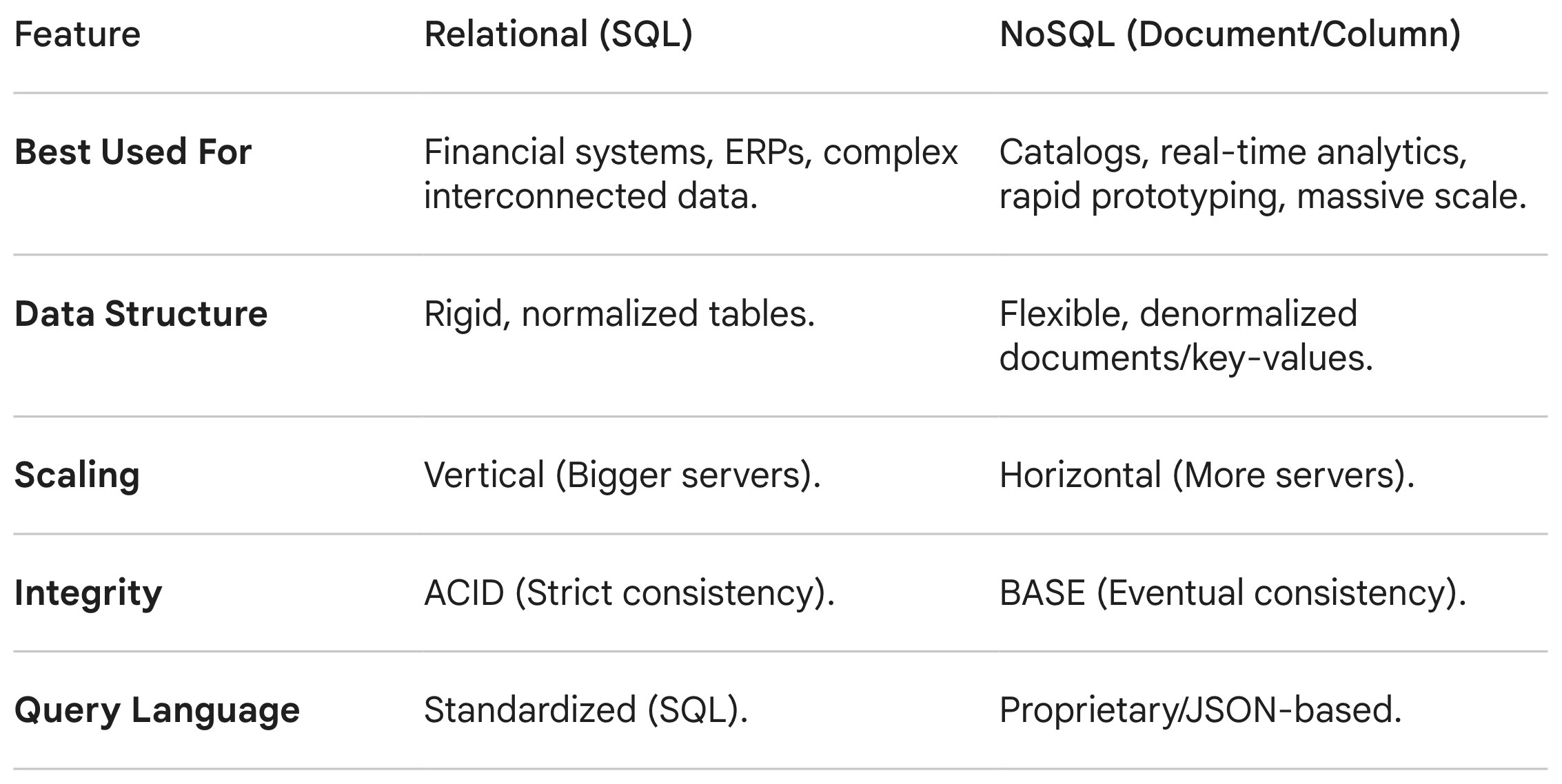
There is no “best” database. A robust modern architecture is almost always polyglot: using PostgreSQL for billing and user accounts, MongoDB for product catalogs, and Redis for session caching—using the exact right tool for the exact right job.
very good read for my commute to work