
The TLB. The Fast Path Your CPU Depends On
How the Translation Lookaside Buffer works and why it makes your code fast (or slow)

“Most performance work is really latency work.”
I only started caring about TLBs when I hit a performance cliff that caching alone couldn’t explain. Everything looked fine: no branch mispredict issues, no dramatic L1 or L2 cache misses, no pathological memory copying. Yet certain access patterns were inexplicably slower.
A page table walk was the culprit. Once I understood how the TLB works and how small it really is, a lot of confusing behavior suddenly became predictable.
This article gives you the mental model I wish I had earlier.
 | COMS W4118 Operating Systems I")
Virtual Memory in Brief
Every process uses virtual addresses. The CPU must translate each virtual address into a physical address. The operating system stores these mappings in page tables, usually in 4 KB units called pages.
Accessing something like:
x := arr[i]causes the CPU to do the following:
virtual address -> page table lookup -> physical address -> cache -> memoryA page table lookup is expensive. On modern machines it can take hundreds of cycles if the CPU has to walk multiple levels of the page table.
The TLB exists to avoid this cost.

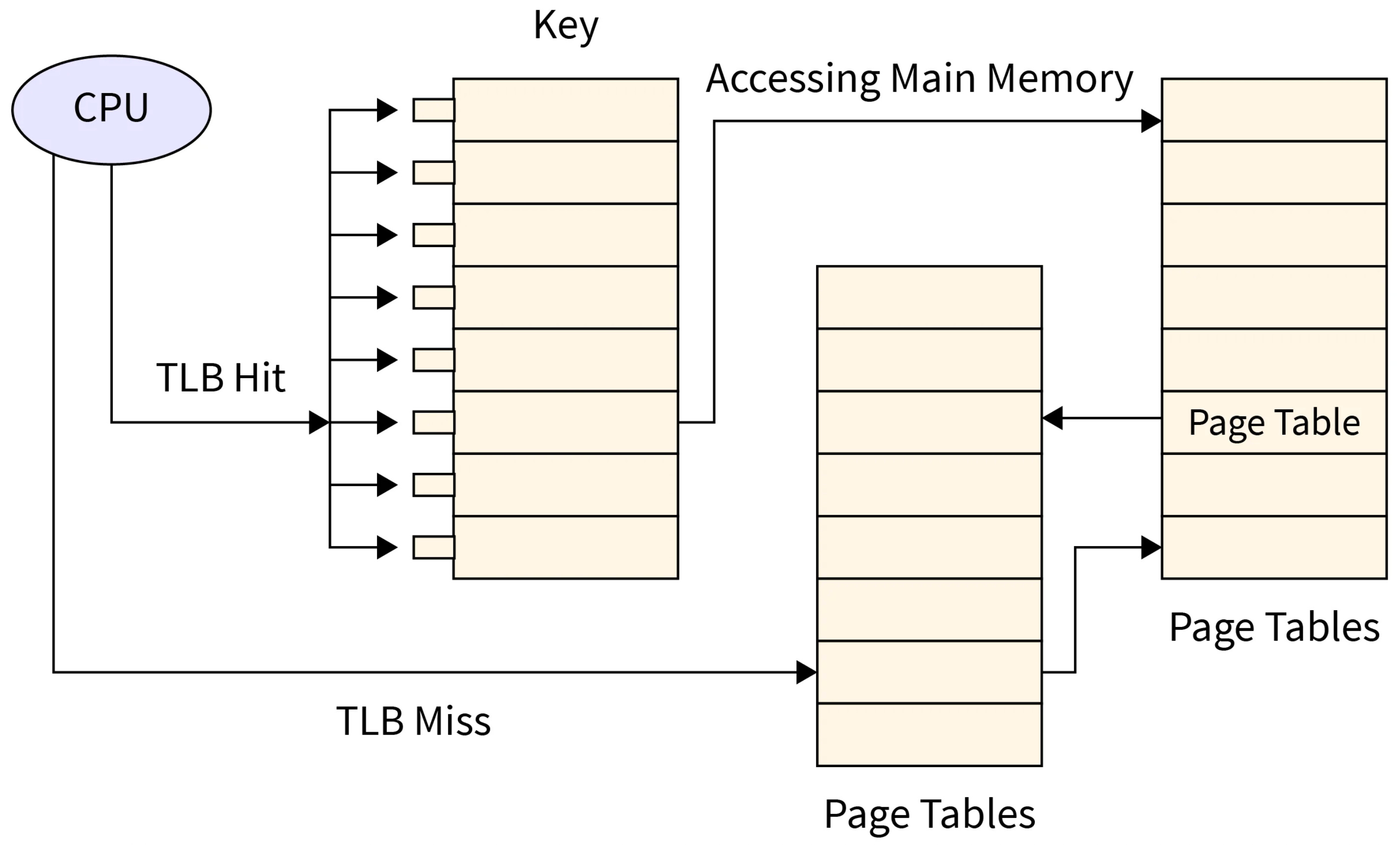
What the TLB Is
A TLB (Translation Lookaside Buffer) is a small cache inside the CPU that stores recent virtual to physical address translations.
Conceptually:
virtual page number -> physical frame numberIf the TLB has the mapping, the load or store continues immediately.
If it does not have the mapping, the CPU performs a page table walk.
TLB Hit vs TLB Miss
Approximate timing:
TLB hit: about 1 to 3 cycles
TLB miss: about 100 to 300 cycles
A TLB miss can be more expensive than an L1 cache miss. The cost adds up quickly in tight loops or random-access patterns.
TLBs Come in Levels
Modern CPUs maintain more than one TLB.
Typical example:
L1 TLB: extremely small and extremely fast
L2 TLB: larger but slower
(And sometimes a shared or last-level TLB)
Sizes vary, but an L1 data TLB might be around:
64 entries, sometimes 128 entries
L2 TLB often contains around 1024 to 2048 entries
This is tiny compared to data caches. You can easily exceed the TLB capacity without realizing it.
Why Sequential Access Is Efficient
Consider a simple loop:
